最近在使用 Qwen 系列模型做一系列 ML 领域的探索,但是当我注意到它的 tokenizer 部分时,却发现有一点奇怪。
具体是怎么个奇怪呢?
我们看一看下面这个例子:
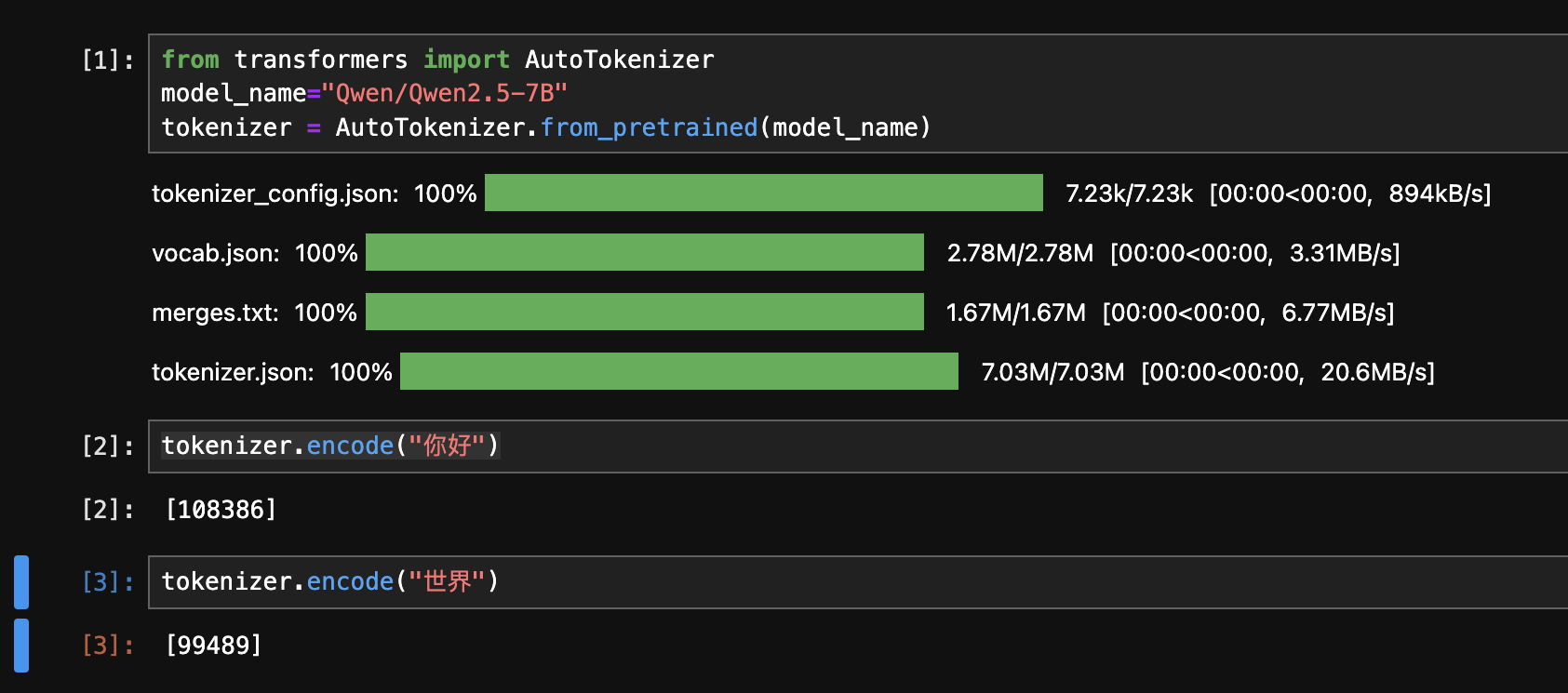
其中,“你好”对应的 token ID 为 108386,而“世界”则为 99489.
但是,当我们查看 Qwen/Qwen2.5-7B 的 token 映射(vocab.json),却会发现 108386 对应的字符串是 "ä½łå¥½",而 99489 对应的则是 ä¸ĸçķĮ.
和原始的输入并不一样,而是变成了乱码。为什么呢?
这是因为,千问系列模型实际上对原始的字节流进行了变换,而这个变换来源于 GPT-2 的 tokenizer。
其原始代码如下:
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
characters the bpe code barfs on.
The reversible bpe codes work on unicode strings. This means you need a large # of unicode characters in your vocab
if you want to avoid UNKs. When you're at something like a 10B token dataset you end up needing around 5K for
decent coverage. This is a significant percentage of your normal, say, 32K bpe vocab. To avoid that, we want lookup
tables between utf-8 bytes and unicode strings.
"""
bs = (
list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
)
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8 + n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
完整的映射与转换
根据原始代码,我们就可以写出一份完整的 Python 代码,用于生成正向和反向的映射, 在遇到乱码后,只需要查找映射,就可以还原出原始的文本。
def bytes_to_unicode():
"""
生成字节到Unicode字符的正向映射表
返回字典:{byte_value: unicode_char}
"""
# 原始保留的字节范围
bs = (
list(range(ord("!"), ord("~") + 1)) + # ASCII可打印字符(33-126)
list(range(ord("¡"), ord("¬") + 1)) + # 西班牙语特殊字符(161-172)
list(range(ord("®"), ord("ÿ") + 1)) # 其他扩展字符(174-255)
)
cs = bs.copy() # 初始字符列表
n = 0
# 遍历所有可能的字节(0-255)
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8 + n) # 超出原始范围的字节映射到更高Unicode码位
n += 1
# 将码位转换为Unicode字符
cs = [chr(code) for code in cs]
return dict(zip(bs, cs))
def get_reverse_mapping(forward_map):
"""
根据正向映射生成反向映射
返回字典:{unicode_char: byte_value}
"""
return {v: k for k, v in forward_map.items()}
# 生成映射表
forward_map = bytes_to_unicode()
reverse_map = get_reverse_map(forward_map)
使用示例
示例1:查看特定字节的映射
# 查看字节值136的映射
byte_val = 136
print(f"字节 {byte_val} 对应的Unicode字符是:{forward_map[byte_val]}")
# 输出:字节 136 对应的Unicode字符是:Ī
示例2:字节到Unicode的转换
def bytes_to_unicode_str(byte_sequence):
return ''.join([forward_map[b] for b in byte_sequence])
# 将"你好"的UTF-8字节转换为Unicode字符串
text = "你好"
byte_sequence = text.encode('utf-8')
unicode_str = bytes_to_unicode_str(byte_sequence)
print(f"原始文本:{text}")
print(f"转换后的Unicode字符串:{unicode_str}")
# 输出:
# 原始文本:你好
# 转换后的Unicode字符串:ä½łå¥½
示例3:Unicode到原始字节的反向转换
def unicode_str_to_bytes(unicode_str):
return bytes([reverse_map[c] for c in unicode_str])
# 将转换后的Unicode字符串还原为原始文本
recovered_bytes = unicode_str_to_bytes(unicode_str)
recovered_text = recovered_bytes.decode('utf-8')
print(f"还原后的文本:{recovered_text}")
# 输出:还原后的文本:你好
完整流程演示
from transformers import AutoTokenizer
def bytes_to_unicode_str(byte_sequence):
return ''.join([forward_map[b] for b in byte_sequence])
def unicode_str_to_bytes(unicode_str):
return bytes([reverse_map[c] for c in unicode_str])
# (缩减后的) 映射生成代码
def b():
bs = list(range(33, 127)) + list(range(161, 173)) + list(range(174, 256))
cs = bs.copy()
n = 0
for b_val in range(256):
if b_val not in bs:
bs.append(b_val)
cs.append(256 + n)
n += 1
return dict(zip(bs, [chr(c) for c in cs]))
def g(f):
return {v: k for k, v in f.items()}
forward_map = b()
reverse_map = g(forward_map)
# 加载Qwen tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B")
# 示例文本
text = "你好世界"
# 步骤1:原始文本 -> UTF-8字节
bytes_data = text.encode('utf-8')
# 步骤2:字节 -> Unicode字符串
unicode_str = bytes_to_unicode_str(bytes_data)
# 步骤3:Unicode字符串 -> tokenizer编码
input_ids = tokenizer(unicode_str, return_tensors="pt")["input_ids"]
# 步骤4:解码过程
decoded_unicode = tokenizer.decode(input_ids[0])
recovered_bytes = unicode_str_to_bytes(decoded_unicode)
recovered_text = recovered_bytes.decode('utf-8')
print(f"原始文本:{text}")
print(f"乱码表示:{unicode_str}")
print(f"解码后的文本:{recovered_text}")
# 输出:
# 原始文本:你好世界
# 乱码表示:ä½łå¥½ä¸ĸçķĮ
# 解码后的文本:你好世界