原始文章 - 由 Google Research 软件工程师 Isaac Caswell 和 Bowen Liang 发布于2020年6月8日。
机器学习(ML)的进步推动了自动化翻译的改进,包括2016年引入的GNMT神经翻译模型,这些改进使得超过100种语言的翻译质量得到了显著提升。然而,尽管如此,最先进的系统在所有翻译任务中仍然远远落后于人类的表现。虽然研究社区已经开发了一些对高资源语言(如西班牙语和德语,这些语言有大量的训练数据)非常有效的技术,但对于低资源语言(如约鲁巴语或马拉雅拉姆语)的翻译质量仍然有待提高。许多技术在受控的研究环境中(例如WMT评估活动)对低资源语言展示了显著的改进,但这些在较小、公开可用数据集上的结果可能不容易转移到大型、网络爬取的数据集中。
在这篇文章中,我们分享了我们在翻译质量方面取得的最新进展,特别是对于那些低资源语言,通过综合和扩展各种最新进展,并展示了如何将这些技术大规模应用于嘈杂的网络挖掘数据。这些技术涵盖了模型架构和训练的改进、数据集中噪声处理的改进、通过M4建模增加的多语言迁移学习,以及使用单语数据。这使得我们在所有100多种语言中将BLEU平均提高了5分,如下图所示。
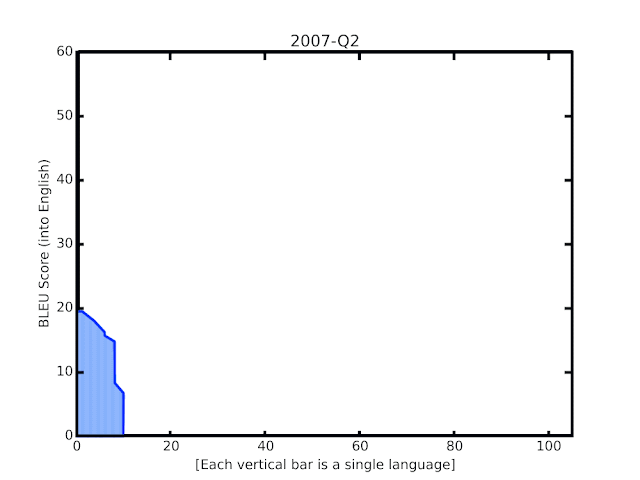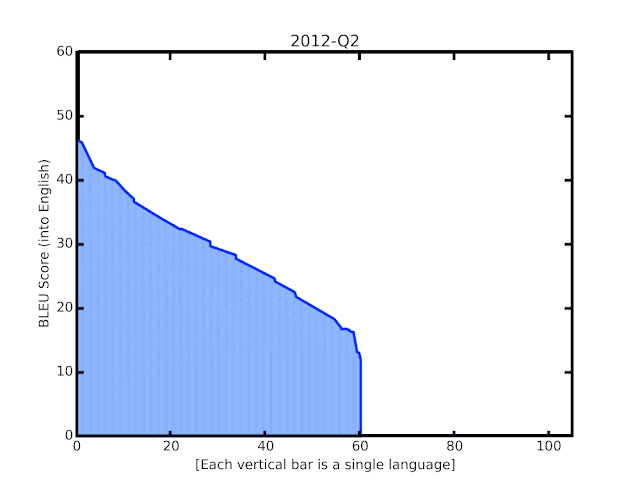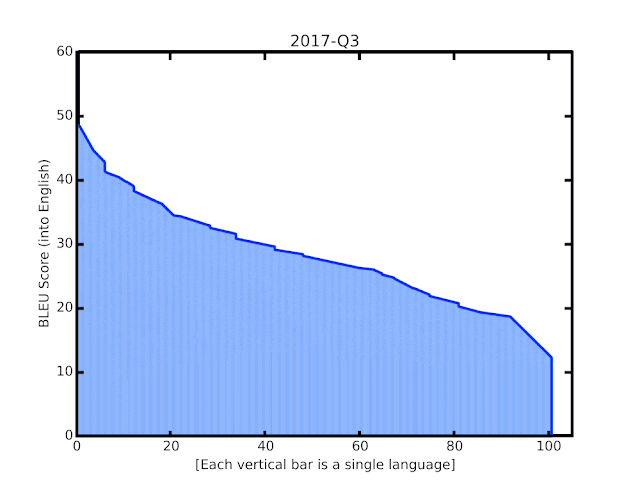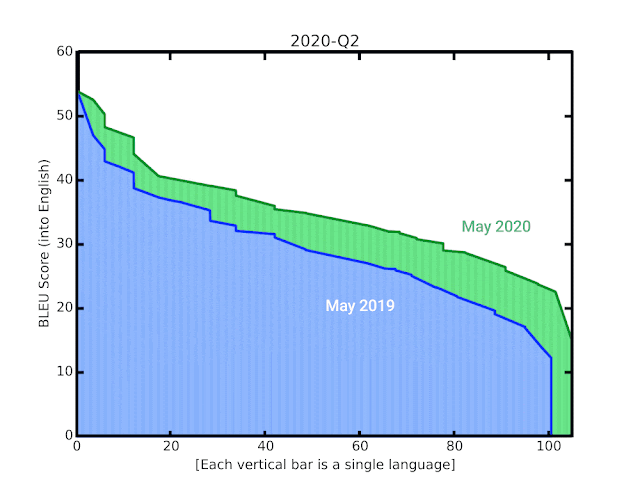
自2006年谷歌翻译诞生以来的BLEU分数。纵轴代表BLEU分数,横轴的每一个柱子代表一种语言。过去一年中实施的新技术带来的改进在动画的末尾突出显示。
高资源和低资源语言的共同进步
混合模型架构
四年前,我们引入了基于RNN(循环神经网络)的GNMT模型,该模型带来了巨大的质量改进,并使谷歌翻译能够覆盖更多语言。在我们解耦模型性能不同方面的研究之后,我们用transformer编码器和RNN解码器替换了原始的GNMT系统,这些模型在Lingvo(一个TensorFlow框架)中实现。Transformer模型在机器翻译方面通常比RNN模型更有效,但我们的研究表明,这些质量提升主要来自transformer编码器,而transformer解码器并不比RNN解码器显著更好。由于RNN解码器在推理时速度更快,我们在将其与transformer编码器结合之前应用了各种优化。最终的混合模型质量更高,训练更稳定,延迟更低。
网络爬取
神经机器翻译(NMT)模型使用从公共网络收集的翻译句子和文档进行训练。与基于短语的机器翻译相比,NMT被发现对数据质量更敏感。因此,我们用一个新的数据挖掘器替换了之前的数据收集系统,该挖掘器更注重精确度而非召回率,从而可以从公共网络收集到更高质量的训练数据。此外,我们将网络爬虫从基于字典的模型切换为基于嵌入的模型,用于14个大型语言对,这使得收集的句子数量平均增加了29%,而没有损失精确度。
建模数据噪声:
噪声严重的数据不仅冗余,还会降低基于其训练的模型的质量。为了解决数据噪声问题,我们利用在去噪NMT训练方面的成果,使用在噪声数据上预训练并在干净数据上微调的初步模型为每个训练样本分配一个分数。然后,我们将训练视为一个课程学习问题——模型首先在所有数据上进行训练,然后逐渐在更小、更干净的子集上进行训练。
特别有利于低资源语言的进步
回译
回译(Back Translation)在最先进的机器翻译系统中被广泛采用,对低资源语言尤其有帮助,因为这些语言的平行数据稀缺。该技术通过合成平行数据来增强平行训练数据(其中每种语言的句子与其翻译配对),其中一种语言的句子由人类编写,但其翻译由神经翻译模型生成。通过将反向翻译纳入谷歌翻译,我们可以利用网络上更丰富的低资源语言的单语文本数据来训练我们的模型。这对提高模型输出的流畅性特别有帮助,这是低资源翻译模型表现不佳的一个领域。
M4建模
对低资源语言特别有帮助的技术是M4,它使用一个单一的巨型模型来在所有语言和英语之间进行翻译。这允许大规模的迁移学习。例如,像意第绪语这样的低资源语言可以从与其他相关日耳曼语言(如德语、荷兰语、丹麦语等)的共同训练中受益,以及与近百种其他语言的共同训练,这些语言可能没有已知的语言联系,但可能为模型提供有用的信号。
评估翻译质量
自动评估机器翻译系统质量的一个流行指标是BLEU分数,它基于系统翻译与人工生成的参考翻译之间的相似性。通过这些最新更新,我们看到在之前的GNMT模型上平均提升了5分的BLEU,其中50种最低资源语言的BLEU平均提升了7分。这一改进与四年前从基于短语的翻译过渡到NMT时观察到的增益相当。
尽管BLEU分数是一个众所周知的近似度量,但它对已经高质量的系统有一些已知的缺陷。例如,一些研究表明,BLEU分数可能会受到翻译腔的影响。当翻译文本不自然,或包含源语言的属性(如词序)时,BLEU分数就可能受到影响。因此,我们对所有新模型进行了人工并排评估,这些评估证实了BLEU分数的提升。
除了整体质量的改进,新模型在处理机器翻译幻觉方面表现出更高的稳健性。机器翻译幻觉是一种模型在接收到无意义输入时产生奇怪“翻译”的现象。这是在少量数据上训练的模型常见的问题,影响了许多低资源语言。例如,当给定一串泰卢固语字符“ష ష ష ష ష ష ష ష ష ష ష ష ష ష ష”时, 旧模型产生了无意义的输出*“Shenzhen Shenzhen Shaw International Airport (SSH)”,似乎试图从声音中找出意义,而新模型正确地将其音译为“Sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh”。
结论
尽管这些进步对于机器来说是令人印象深刻的,但必须记住,尤其是对于低资源语言,自动翻译质量远未完美。这些模型仍然会犯典型的机翻错误,包括在特定主题领域上表现不佳、混淆某个语言的不同方言、产生过于死板的翻译,以及在非正式的口语风格文本上表现不佳。
尽管如此,通过这次更新,我们自豪地为108种支持语言中的最低资源语言提供了相对连贯的自动翻译。我们感谢学术界和工业界活跃的机器翻译研究社区所做出的研究贡献。
致谢
这项工作建立在Tao Yu、Ali Dabirmoghaddam、Klaus Macherey、Pidong Wang、Ye Tian、Jeff Klingner、Jumpei Takeuchi、Yuichiro Sawai、Hideto Kazawa、Apu Shah、Manisha Jain、Keith Stevens、Fangxiaoyu Feng、Chao Tian、John Richardson、Rajat Tibrewal、Orhan Firat、Mia Chen、Ankur Bapna、Naveen Arivazhagan、Dmitry Lepikhin、Wei Wang、Wolfgang Macherey、Katrin Tomanek、Qin Gao、Mengmeng Niu和Macduff Hughes的贡献之上。