引言
时至今日,我们已经习惯了用搜索引擎寻找我们需要的信息。
比如,你想知道世界上最高的山峰是哪座,你只需要打开一个你喜欢的搜索引擎,输入“世界上最高的山峰”,它就能在不到一秒的时间内搜寻到结果并返回给你:珠穆朗玛峰。
再比如,你在一篇计算机文章中看到了一个你不认识的新词汇 “python”,你想了解关于它的信息,于是你在搜索引擎中输入 “python”。
敲击回车后,百度向你展示了 广告 python 官网、python 的百度百科和…… 额怎么又是广告 右栏中,展示了相关术语和热搜。
必应的版面很丰富。 在顶部显示了 Python 以及它的定义:编程语言,和关于它的一些链接,如在线编译器、文档、教程等,接着用了一个小卡片显示了它的下载地址。左栏和右栏分别是 Python 官网中各个板块的链接,和关于 Python 的百科信息及相关搜索。正文部分,除了 Python 官网的简介和链接外,还详细展示了 Python 官网的每一个板块,并附上了可以直接在 Python 官网中搜索的输入框。
到了搜索引擎老大哥 Google,它的信息展示相比必应没有那么复杂。在搜索结果上方,一行小字显示出谷歌在 0.45 秒内找到了关于此关键词的约 14.2 亿条结果。而在第一个搜索结果中,展示了 Python 官网的链接、描述、和必应相同的搜索框、以及官网中的部分板块。右侧则和必应相同,展示了 Python 的百科信息和相关搜索。
那么,问题来了,为什么搜索引擎能如此快地找到如此多的信息,它背后又有哪些技术支撑呢?
搜索引擎的核心技术大致可分为三个部分:爬虫、索引和排序。
爬虫
爬虫,又称网络蜘蛛(web crawler),是搜索引擎用于找到互联网上数以亿计网页的关键。
互联网中的每一个网页上,都可能包含许多 超链接。这些超链接里面,是别的网页的地址。这也就是互联网 互联 的根本。正是因这种网站之间相互链接的关系,搜索引擎才能收录互联网上数不清的网页。
搜索引擎的爬虫实际上是一个不断搜寻网站,访问其中的超链接的程序。在它运行时,首先需要提供一些网站作为种子,如雅虎、亚马逊、新浪、网易等。接着,爬虫就会开始“串门”,模拟人类访问这个网站,网站返回的页面源代码后,爬虫程序会分析代码,找出网站的标题、描述、正文、Logo 等,并将它们存入搜索引擎的数据库。同时,爬虫还会找到网站中的链接,并继续“串门”,重复之前的步骤。这样,爬虫就能顺着这一个个的链接爬遍互联网。
但是,空有爬虫最多只能让你获得一个巨大的网页数据库,并不能实际搜索。因此,这时候便需要 索引 登场了。
索引
谷歌曾在“Google 搜索的工作原理”的页面中写道
The Google Search index contains hundreds of billions of webpages and is well over 100,000,000 gigabytes in size.
它的意思是:谷歌搜索索引中包括数千亿的网页,它们的总大小超过了 1 亿 GB。
很显然,谷歌并不可能在零点几秒内将几千亿个网页挨个搜索一遍,找出你想要的结果。实际上,搜索引擎能快速找到信息的真正秘密在于刚刚句子中的一个词: index,即 索引。
接下来,让我们看看搜索引擎的索引到底是什么。
爬虫爬取到网站的信息后,首先会对网页的内容进行 分词。分词,顾名思义,就是将一段文字以词语作单位分割开来。
英文由于以空格隔开每个词语的语法习惯,几乎不需要分词。但搜索引擎仍会对其中单词的变体,如过去式、现在分词、复数形式等进行还原。
中文分词则要复杂一些,它通常包括一个巨大的词典,通过向前或向后匹配句子中的最长子串进行分词。这个过程略微有点复杂,好的中文分词还可能包括消歧义算法,或利用机器学习、神经网络等 AI 算法,在此不多赘述。
对网页内容分词之后,接下来就是将它们存入索引。索引可以简单理解为一个表格,它包括关键词和对应的网页。
我们假设我们的数据库内有三个网页,它们看起来是这样的:
| 网页 | 内容 |
|---|---|
| A | iPhone 13 是苹果公司于 2021 年在 Apple Park 发布的 iPhone 手机。 |
| B | Apple Park,是苹果公司新总部大楼,乔布斯生前所设计,位于美国加利福尼亚州库比蒂诺市。 |
| C | 史蒂夫·乔布斯,是苹果公司的创始人之一。先后领导和推出了 iMac、iPod、iPhone、iPad 等著名电子产品 |
而如果我们对它们编制一个索引,它长这样:(此表仅为部分索引)
| 关键词 | 网页 |
|---|---|
| iPhone | A, C |
| Apple | A, B |
| Park | A, B |
| 苹果 | A, B, C |
| 2021 | A |
| 13 | A |
| 乔布斯 | B, C |
| 公司 | A, B, C |
| …… | …… |
这是一个由关键词和包含关键词的网页列表所构成的一张表。
当然,真实的搜索引擎并不只有 3 篇文章,它们的索引也要比这复杂的多,但是我们可以通过这个简单的模型,来揭示索引的核心思想。
比如,当输入“iPhone 13”时,搜索引擎不会在 ABC 三篇网页的每一个词中搜索 “iPhone”和 “13”,而是会直接在索引中分别找出“iPhone”和“13”对应的网页列表,也就是这部分。
| 关键词 | 网页 |
|---|---|
| iPhone | A, C |
| 13 | A |
我们可以明显看出,网页 A 和网页 C 中都包含了其中至少一个关键词,而网页 A 同时包含了“iPhone”和“13”这两个关键词。
搜索引擎会同时返回网页 A 与网页 C,但是网页 A 的排名大概率会比 C 高。
那么这就要引出下一个环节——排序 了。
排序
排序,几乎是搜索引擎算法最重要的部分。因为光能搜索出东西还不够,搜索引擎还需要对结果进行排序,才能确保最重要,最关键的信息能呈现在搜索结果的前几位。
关键词匹配程度
比如,在之前我们构建的一个迷你搜索引擎的模型中,当我们输入“iPhone 13”时,搜寻到了 A、C 两个网页符合我们的关键词。但是,搜索引擎该把谁排在第一位呢?很显然,网页 A 同时包含“iPhone”和“13”两个关键词,而网页 C 仅包含一个,因此搜索引擎可能会把 A 排在 C 的前面。那么这就是搜索引擎排序算法的一个最简单的因素——关键词匹配程度。
搜索排序算法的影响因素有很多,并且不同的搜索引擎都会有自己的独家算法,这里我们简单介绍几个。
辅助因素
除了刚刚提到的关键词匹配程度外,搜索引擎还会检测关键词匹配的数量和位置。成熟的搜索引擎的索引中,不仅会记录哪些网页包含某个关键词,还会记录该网页中关键词的位置和数量。通常来说,在网页标题出现的关键词可能比正文或注释中出现排名高,而匹配关键词多的网页比匹配少的排名高。此外,搜索排名还可能根据用户点击链接的次数、浏览时长来决定。
PageRank
当然,还有两个经典——PageRank 和竞价排名
PageRank 是谷歌早期对搜索结果排序的一种重要算法,接下来,让我们用一个简单的模型来理解 PageRank。
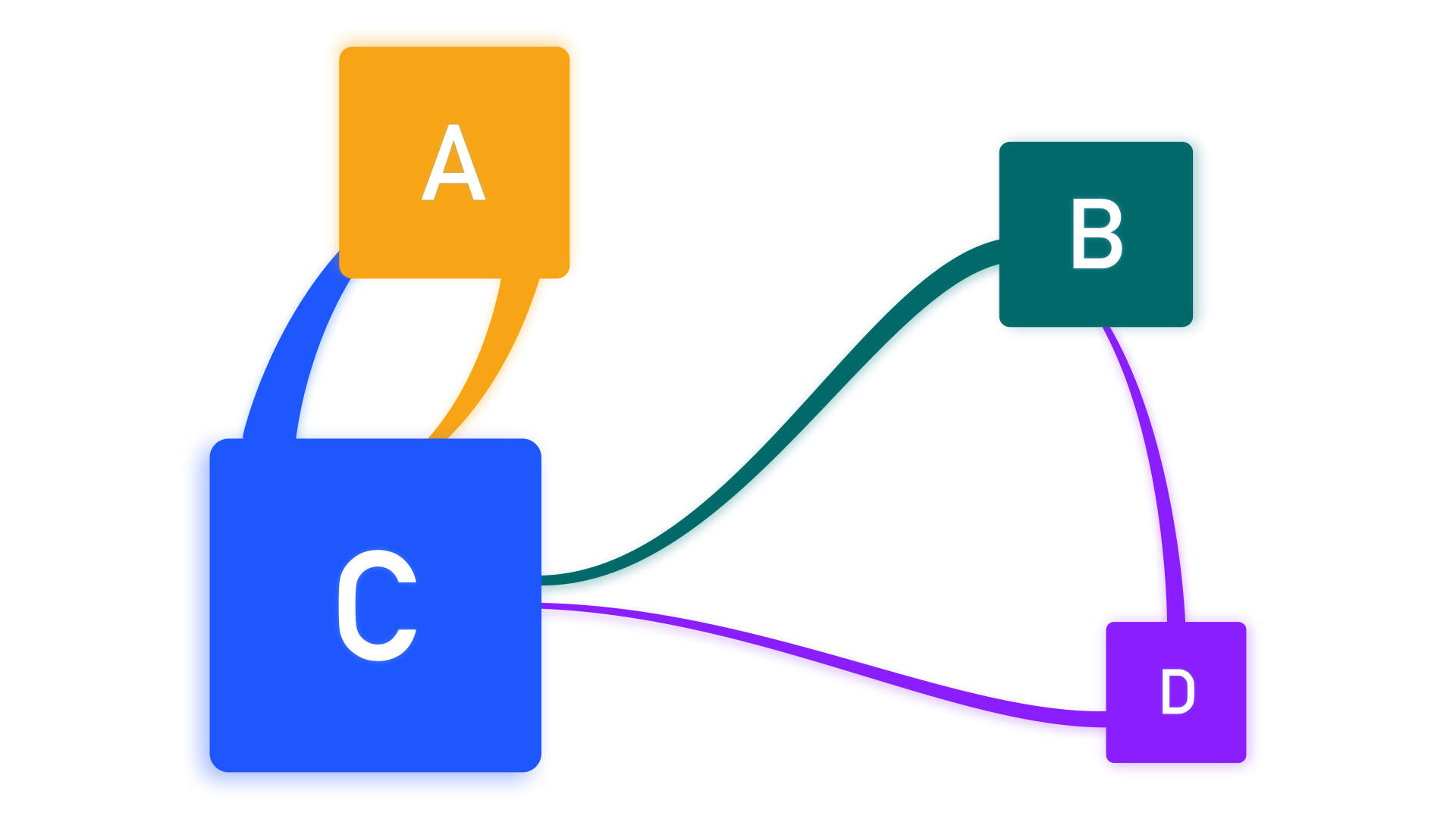
我们来看看这幅图。其中,线条表示网站之间互相链接的关系,方块的大小表示网站的 PageRank 值。
D 因为没有被任何页面链接,所以 PR 值最低,而 C 被 3 个页面链接,PR 值最高,而 B 与 A 虽然都只被一个网页链接,但 A 的 PR 值比 B 高,这是因为链接 A 的 C 的 PR 值比链接 B 的 D 高。
换句话说,链接你的网页越多,你的 PageRank 就越高;同时,链接你的网页本身的 PageRank 越高,你的 PageRank 也越高。
根据谷歌的解释,PageRank 的思想类似于科学文献的引用。通常来说,如果一篇文章被引用的次数越多,我们就认为该论文的学术价值越高。同样地,Google 认为,如果一片网页的质量很高,那么就会有很多网页“引荐”它,即为它创建链接。同时,如果你的网页被质量高的网页“引荐”,那么 Google 就会认为你的网页质量也同样不错。
不过,PageRank 也有缺点,比如新网页的 PageRank 可能很低,同时,一些人为了使他们网页的 PageRank 值更高,会恶意创建链接。因此,现在 PageRank 在谷歌的排名算法中,地位已经越来越低。
竞价排名
刚才我们讲了 Google 排名算法的经典 PageRank,而下面介绍的则是百度的经典——“臭名昭著”的竞价排名。
百度在应用开始提到的关键词匹配、点击量等等基础算法之外,还应用了一个不能称之为算法的机制,也就是竞价排名。
竞价排名,可能熟悉“魏则西事件”的朋友可能有所耳闻,即通过付钱的方式来使自己的网页排在搜索结果中更靠前的位置。这个机制非常简单易懂,给钱,我把你的网页放到前面。
当然,“魏则西事件”也让百度的竞价排名步入人们的视野,百度的口碑也慢慢崩坏。
对于我而言,自从我发现了必应后,几乎再没用过百度。平时搜索,我绝大部分情况都会用必应,偶尔会用谷歌和 Ecosia。我曾几次在需要搜索本地内容时尝试过百度,可它全系产品的糟糕体验让我难以使用下去。
我希望终有一天,我们能有一款像谷歌一般优秀的搜索引擎,而不是有着搜索功能的广告推送机。让答案不只在“灯火阑珊处”。
参考文献
[1] 常璐, 夏祖奇. 搜索引擎的几种常用排序算法 [J]. 图书情报工作, 2003, 47(6): 70-73,88.